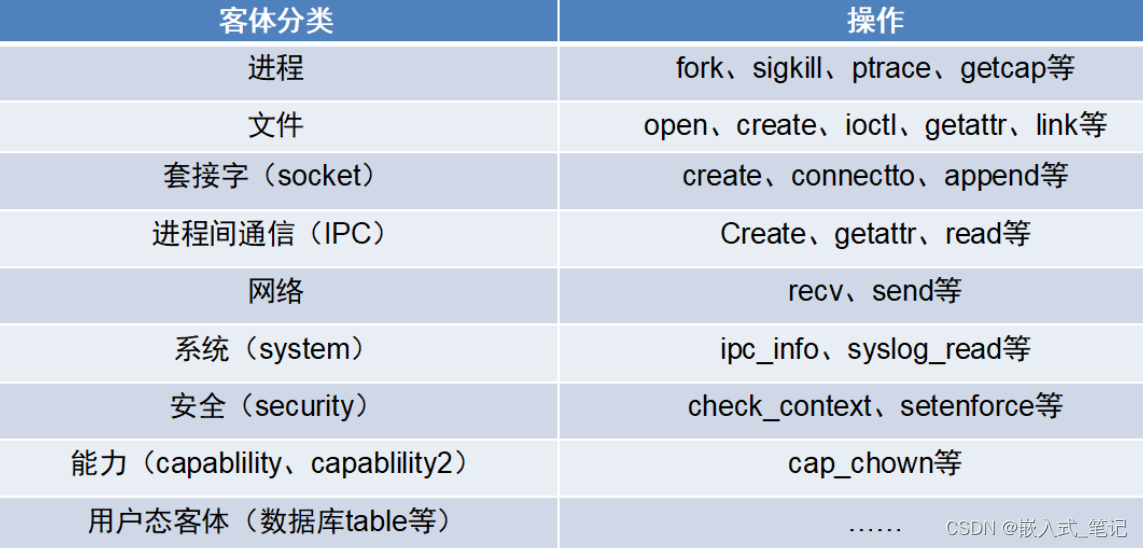
24年1月,上海交大、上海人工智能实验室、中科院联合发布Vlogger:make your dream a vlog。该论文主要工作是生成超过5分钟的视频博客vlog。鉴于现有文本到视频T2V生成方法很难处理复杂的故事情节和多样化的场景,本文提出了一个名为Vlogger的通用AI系统,将长视频生成任务优雅地分解为四个阶段,包括 (1) 剧本Script,(2) 演员Actor, (3)制作人ShowMaker 和 (4) 配音员Voicer。此外,论文还提出了一种名为ShowMaker的视频扩散模型,以提高T2V生成和预测的性能。最终的实验结果表明,该方法在零样本T2V生成和预测任务中取得了最先进的性能。
总体说来,Vlogger有四大特色:
- 提出了一个新颖的Video Diffusion视频生成扩散模型—ShowMaker,以生成每个场景的视频片段。该模型采用了一种独特的时空增强块STEB,能够自适应地利用场景描述和演员图像作为文本和视觉提示,以增强剧本和演员的时空一致性。
- 开发了一种概率模式选择机制,通过混合训练T2V生成和预测,增强了ShowMaker的能力。在推理阶段,通过将生成和预测模式进行序列组合,ShowMaker能够生成具有可控持续时间的视频片段,从而使Vlogger可以根据LLM导演的剧规划划生成具有理想持续时间的视频博客vlog。
- 提出了一种通用AI系统Vlogger,通过自上而下规划和自下而上拍摄的可解释性的合作,它可以从开放世界的描述中生成超过5分钟的vlogs。
- Vlogger通过将用户故事优雅地分解成一系列拍摄场景,并设计不同场景中参考演员图像,从而克服了长视频生成任务中遇到的挑战。这可以减少突然的镜头变化导致空间—时间不连贯的问题,同时利用场景文本和演员图像的明确指导。
该工作有很大的实用性,制作出的效果也特别好,在视频制作、视频营销、视频学习、视频推荐和视频修复领域很有推广价值。
Abstract
在这项工作中,我们提出了Vlogger,这是一种通用AI系统,按用户描述生成分钟级视频博vlog。与几秒钟的短视频不同,视频博客Vlog通常包含复杂的故事情节和多样化的场景,这对于大多数现有的视频生成方法来说是一个挑战。为了突破这个瓶颈,我们的Vlogger巧妙地利用大型语言模型 LLM作为导演Director,并将vlog的长视频生成任务分解为四个关键阶段,我们调用各种基础模型来扮演vlog专业人士的关键角色,包括 (1) 剧本Script,(2) 演员Actor, (3)制作人ShowMaker 和 (4) 配音员Voicer。通过这种模仿人类的设计,Vlogger可以通过自上而下规划和自下而上拍摄的可解释性的合作生成vlogs。此外,我们引入了一种新的视频扩散模型ShowMaker,它在Vlogger中充当摄像师,用于生成每个拍摄场景的视频片段。将剧本和演员作为文本提示和视觉提示,可以有效地增强vlog的时空连贯性。此外,我们为ShowMaker设计了一个简洁的混合训练范式,提高了它在T2V生成和预测方面的能力。最后,大量实验表明,我们的方法在零样本T2V生成和预测任务上实现了最先进的性能。更重要的是,Vlogger可以从开放世界描述中生成超过5分钟的vlog,而不会丢失剧本和演员的视频一致性。
1. Introduction
Vlogs代表了一种独特的博客形式,其特点是利用视频作为主要媒介而不是文本。由于动态场景中有更多的实时表达,vlog已成为数字世界中最流行的在线共享方式之一。在过去的几年里,扩散模型的显著成功对视频生成有很大影响。
- IMAGEN VIDEO: HIGH DEFINITION VIDEO GENERATION WITH DIFFUSION MODELS
- Make-A-Video: Text-to-Video Generation without Text-Video Data
- ModelScope Text-to-Video Technical Report
- LAVlE: High-Quality Video Generation with Cascaded Latent Diffusion Models
- NUWA-XL: Diffusion over Diffusion for eXtremely Long Video Generation
- Show-1: Marrying Pixel and Latent Diffusion Models for Text-to-Vide Generation
因此,一个自然的问题是,我们能否构建一个通用人工智能系统来自动生成精彩的vlog?
遗憾的是,目前的大多数视频扩散方法主要通过图像扩散模型的时间适应来生成短视频。相比之下,vlog通常在开放世界中生成分钟级长视频。最近,在长视频生成方面取得了一些尝试。
- Phenaki: Variable Length Video Generation From Open Domain Textual Description
- NUWA-XL: Diffusion over Diffusion for eXtremely Long Video Generation
然而,这些早期的工作要么需要对大型精确字幕、长视频数据集进行大量训练,要么遭受镜头变化明显不连贯。因此,生成一个具有复杂叙事和多场景的分钟级vlog仍然具有挑战性。我们注意到成功的vlog制作在现实世界中是一个系统工作,其中关键工作人员参与剧本创建、演员设计、视频拍摄和编辑。受此启发,我们认为,生成长篇视频博客需要详细的系统规划和拍摄过程,而不是简单地设计一个生成模型。

图 1. Vlogger简介。基于用户故事,Vlogger利用大型语言模型LLM作为导演,并将分钟级长视频vlog生成任务分解为Script,Actor,ShowMaker and Voicer四个关键阶段。ShowMaker是一种新颖的视频扩散模型,可以生成每个拍摄场景的视频片段,具有剧本和演员的一致性。
因此,我们提出了一种用于vlog生成的通用 AI 系统,即Vlogger,它可以通过在核心步骤中,利用各种基础模型,模仿各种专业人士来巧妙地解决这些困难任务。如图 1 所示,由于语言知识理解的强大能力,我们首先聘请大型语言模型LLM作为导演,例如GPT-4。给定一个用户故事,这个导演安排了一个四步的 vlog 生成计划。
- 剧本Script。首先,我们为LLM导演引入了一种渐进剧本创建范式。通过这种范式中从粗到细的指令,LLM导演可以有效地将用户故事转换为剧本,该剧本通过多个拍摄场景及其相应的拍摄持续时间来充分描述故事。
- 演员Actor。在创建脚本后,LLM导演再次读取剧本以总结演员,然后调用角色设计师(例如,SD-XL)在vlog中生成这些演员的参考图像。
- 制作人ShowMaker。在剧本文本和演员图像的指导下,我们开发了一种新颖的ShowMaker作为摄像师,它可以有效地为每个拍摄场景生成具有时空一致性的可控持续片段。
- 配音员Voicer。最后,LLM Director 调用语音器(例如,Bark )将 vlog 与剧本字幕相关联。
需要注意的是,我们的 Vlogger 克服了以前在长视频生成任务中遇到的挑战。一方面,它将用户故事优雅地分解为许多拍摄场景,并设计了可以参与 vlog 中不同场景的演员图像。在这种情况下,它可以在场景文本和演员图像的显式指导下减少突然镜头变化的时空不一致性。另一方面,Vlogger 为每个场景制作单个视频片段,并将它们无缝集成到单个内聚 vlog 中。因此,这绕过了大规模长视频数据集繁琐的训练过程。通过自顶向下规划和自底向上拍摄之间的这种协作,Vlogger 可以有效地将开放世界故事转换为分钟级长的视频博客 vlog。
此外,我们想强调的是,ShowMaker 是一个独特的视频扩散模型,旨在生成每个拍摄场景的视频片段。从结构的角度来看,我们在该模型中引入了一种新颖的时空增强块 STEB。这个块可以自适应地利用场景描述和演员图像作为文本和视觉提示,仔细引导ShowMaker增强剧本和演员的时空一致性。从训练的角度来看,我们开发了一种概率模式选择机制,该机制可以通过混合训练文本到视频 T2V 生成和预测来提高 ShowMaker 的容量。更具体地说,在推理阶段通过生成和预测模式的顺序组合,ShowMaker 可以生成持续时间可控的视频片段。这允许我们的 Vlogger 根据 LLM 导演剧本中每个场景的规划,生成具有更长持续时间的 vlog。
最后,通过在流行的视频基准中进行昂贵的实验,我们的方法在零样本T2V生成和预测方面实现了最先进的性能。更重要的是,Vlogger 尽管只使用了 66.7% 的训练视频,但优于众所周知的长视频生成方法,如Phenaki。值得注意的是,Vlogger 能够生成超过 5 分钟的 vlog,而不会丢失视频中剧本与演员的连贯性。
2. Related Works
Text-to-Video Generation
与传统的无条件和类条件视频生成不同,T2V生成侧重于自动将文本描述转换为视频。这是一个具有挑战性的任务,因为它涉及理解文本语义并将其翻译成视频内容。这通常需要强大的跨模态算法、大型计算资源和广泛的视频数据。基于扩散模型在文本到图像 T2I 生成方面的成功,一系列此类工作最近转移到 T2V 生成。然而,无论是从头开始还是从T2I模型开始训练,大多数方法主要致力于从简单的描述中生成几秒钟的短视频。相比之下,我们的 Vlogger 可以生成具有复杂故事的分钟级长视频博客。
Long Video Generation
长视频的生成主要依赖于并行或自回归结构。然而,这些早期的工作仍然面临 vlog 生成的挑战。一方面,并行方式可以通过从粗到细的生成来缓解时空内容不连贯问题。然而,这种方法需要对大型、标注良好的长视频数据集进行广泛而费力的训练。另一方面,自回归方式可以通过使用滑动窗口迭代应用短视频生成模型来缓解对训练长视频的大量数据要求。然而,这种解决方案往往会出现明显的镜头变化和长期不连贯,这在生成包含复杂叙事和多个场景的视频博客时就会成为问题。值得一提的是,社区逐渐意识到将高阶推理任务委托给LLM,对视觉任务有很大的帮助。我们的Vlogger将LLM引入到长视频生成领域,并通过自顶向下规划和自底向上拍摄的合作,有效地解决了以往方法中训练负担和内容不连贯问题。
3. Method
3.1. Overall Framework of Vlogger
为了生成分钟级别的视频博客 vlog,Vlogger 利用 LLM 作为导演,它可以在规划和拍摄阶段通过四个关键角色有效地分解这个生成任务。如图 1 所示,LLM Director首先在规划阶段创建剧本Script和设计演员Actor。基于 Script 和 Actor,制作人 ShowMaker 在拍摄阶段为每个场景生成一个视频片段,配音员Voicer为这个片段配字幕。最后,可以将所有片段组合成一个 vlog。
3.1.1 Top-Down Planning
vlog 往往来自一个用户故事,其中包含许多镜头变化的多样化内容。显然,通过将如此复杂的故事直接输入到视频生成模型中,产生分钟级长 vlog 具有挑战性。我们建议利用LLM作为导演,并通过图 2 中的自顶向下规划对用户故事进行分解。
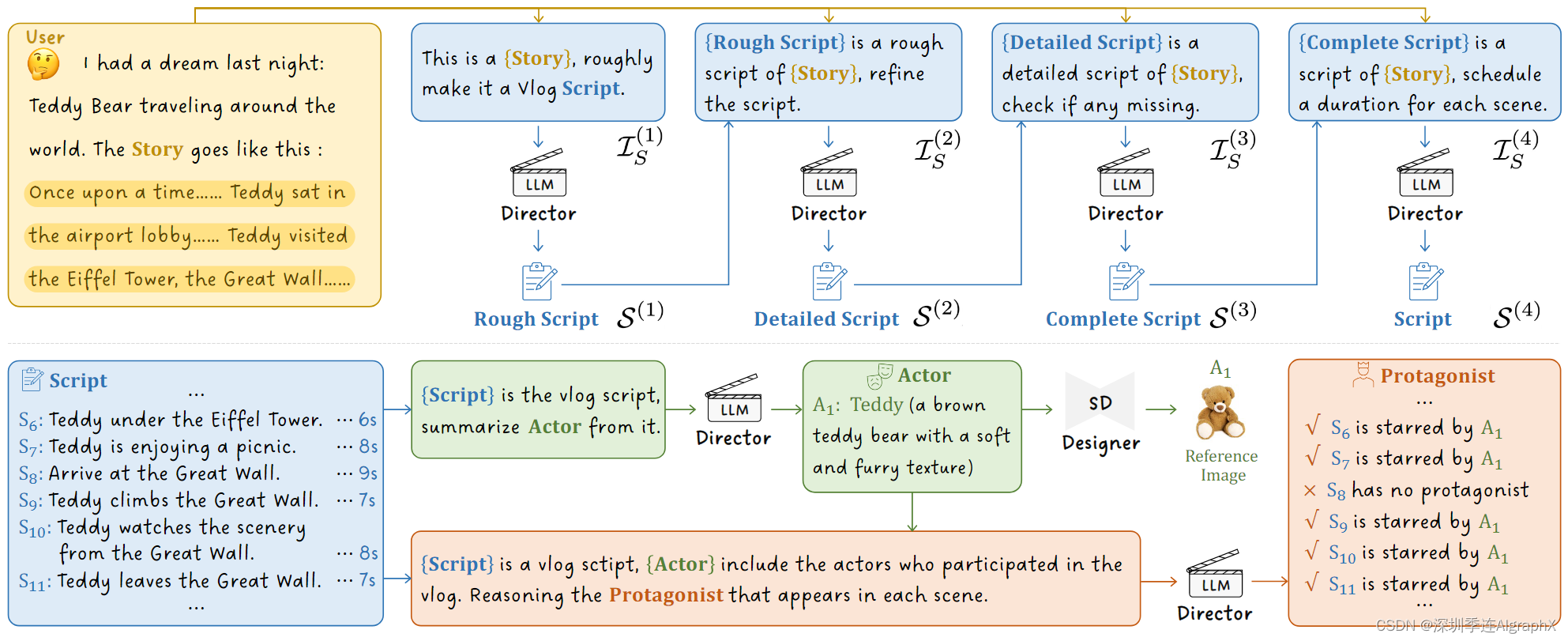
图 2. 自上而下的规划。通过与LLM的四轮对话,我们逐渐将用户故事转化为最终的剧本。在此基础上,我们进一步提取演员参考图像,然后确定各个演员将在哪个场景中出演。
Script Creating
首先,我们将使用故事解析为剧本,该剧本通过许多拍摄场景明确地描述了这个故事。在这种情况下,我们可以为每个拍摄场景生成一个视频片段,而不是从整个故事中繁琐的学习长视频。由于LLM在语言理解方面表现出了令人印象深刻的能力,我们将用户故事输入这样一个导演Director(即LLM)进行剧本生成。如图 2 所示,我们引入了一种渐进式创建范式,它可以通过从粗到细的步骤有效地解析故事。
![]()
给定用户故事 U 和创建指令 I (i)/S ,LLM Director 从前一个 S(i-1) 生成当前剧本 S(i)。更具体地说,有四个步骤,包括
(1) 粗略Rough。首先,LLM 从故事中生成脚本的基本草稿。
(2) 详细Detailed。然后,LLM 细化粗略的脚本。
(3) 完整Completed。接下来,LLM检查详细的脚本是否遗漏了故事的重要部分。
(4) 时间表Scheduled。最后,LLM根据场景内容为完整剧本中的每个场景分配一个拍摄持续时间。为方便起见,我们将最终剧本表示为 S,如下所示。它包含 N 个拍摄场景的描述 {S1,..., SN } 及其分配的持续时间 {T1,..., TN }。
Actor Designing
生成剧本后,是时候在 vlog 中设计演员了。如图 2 所示,我们请求LLM导演从剧本S中总结演员列表 A
![]()
其中 IA 是演员摘要的指令。然后,根据演员描述,LLM 导演调用设计人员来生成这些演员 R 的参考图像
![]()
由于其高质量的生成,我们选择 Stable Diffusion XL 作为角色设计者。最后,基于剧本 S 和 演员A,LLM 导演决定剧本的每个拍摄场景中的领先参与者(即主角)
![]()
其中 Ip 是主角选择的指令。生成的文档 P 与剧本 S 对齐,其中 Pn 描述了哪个演员出现在场景 Sn 中。例如图 2 中 S6 的 A1。
3.1.2 Bottom-Up Shooting
通过上面的自顶向下规划,LLM 导演灵活地将复杂的用户故事分解为几个场景,并为每个场景设计演员参考图像。这种方式大大降低了 vlog 生成的难度,因为我们可以通过自下而上的拍摄生成 vlog,即我们只需要为每个拍摄场景生成视频片段,并将它们全部组合成一个 vlog。
ShowMaker Shooting
为了生成拍摄场景的视频片段,我们引入了一种新的 ShowMaker 作为视频拍摄者,它具有两个不同设计的视频扩散模型。首先,重要的是保持生成片段中剧本和演员的时空连贯性。因此,我们的 ShowMaker 不仅采用场景描述 Sn 作为文本提示,也将场景 Rn 的演员图像作为视觉提示。其次,每个场景都被分配了剧本中的拍摄持续时间。为了控制每个场景的持续时间,我们的 ShowMaker 包含两个学习模式,包括图 3 中的生成和预测。
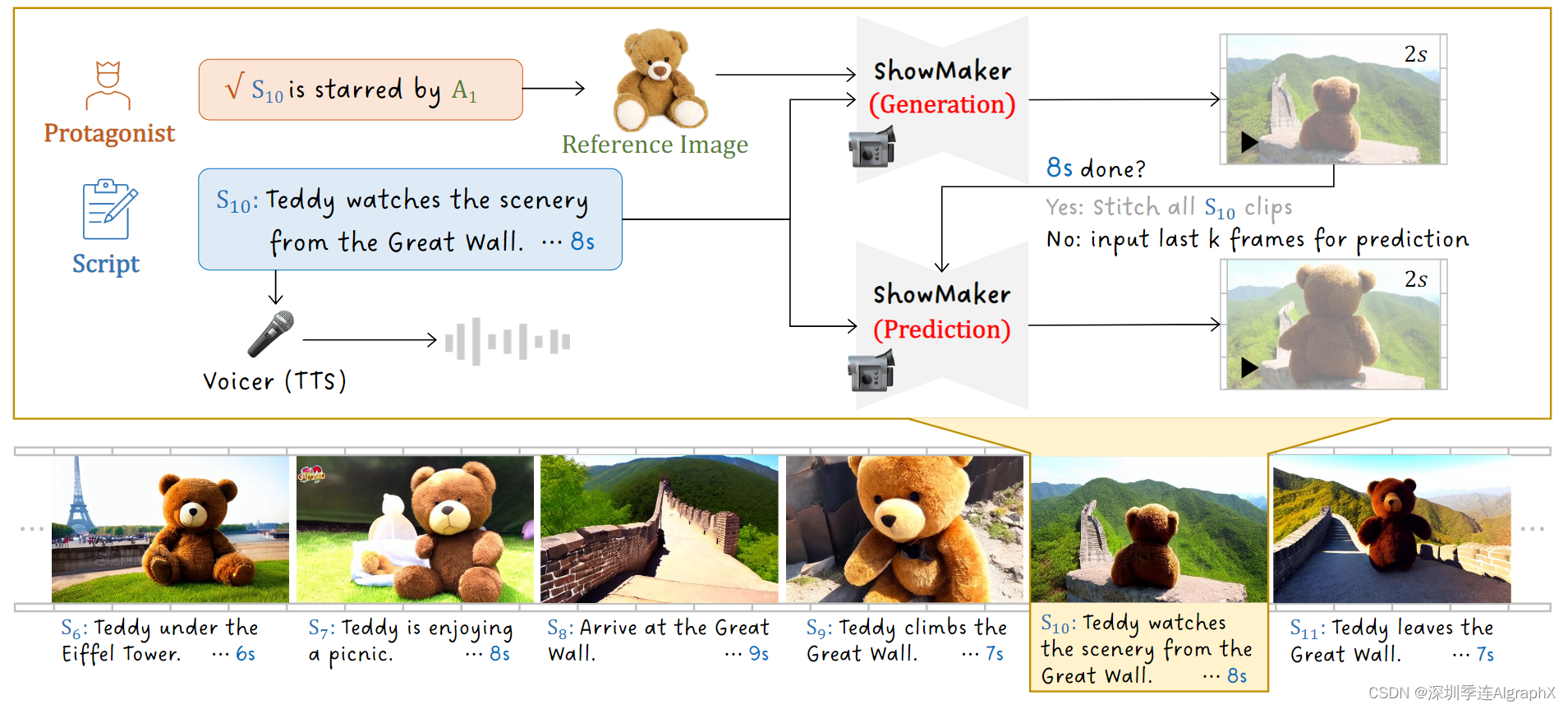
图 3. 自底向上拍摄。对于每个场景,ShowMaker可以通过使用剧本描述和演员图像作为文本和视觉提示,生成具有剧本和演员时空一致性的视频片段。此外,ShowMaker可以有效地控制片段的持续时间,在推理中依次进行生成和预测。最后,我们应用文本到语音(TTS)模型作为配音器。
具体来说,它从生成模式开始。对于拍摄场景 n,我们将其脚本描述 Sn 和演员参考图像 Rn 输入到 ShowMaker 中
![]()
它从噪声 Clip N (1)/n 生成该场景 C(1)/n 的第一个视频剪辑。如果该剪辑的持续时间小于脚本中分配的持续时间 Tn,我们继续执行预测模式,即当前 Clip C(j)/n (k) 的最后 k 帧用作上下文,当从噪声输入 N (j+1)/n 生成下一个剪辑时
![]()
请注意,在预测模式下不需要演员参考图像,因为该演员的外观已在当前 Clip C(j)/n (k) 中显示为用于预测的输入。该预测过程停止,直到总持续时间达到该场景的分配 Tn。随后,我们将所有剪辑组合为该场景的视频片段,即 Cn = {C(1)n ,..., C(J)n }。
Voicer Speaking
为了提高 vlog 的完整性,我们应用 Text-To-Speech 模型(例如 Bark 作为 Voicer,它将场景描述 Sn 转换为相应的音频 On = Bark(Sn)。最后,我们将此音频添加到相应的视频片段 Vn = On ⊕ Cn 上,并将有声视频片段组合成一个完整的 vlog,即 V = {V1,..., VN }。
3.2. ShowMaker
如第 3.1.2 节所述,ShowMaker 在生成拍摄场景的视频片段中起着至关重要的作用。在这项工作中,我们为它引入了一个文本到视频扩散模型。它遵循潜在扩散模型的风格。在扩散阶段,我们将高斯噪声逐步添加到训练片段的潜在代码中。在去噪阶段,我们在任何迭代步骤从有噪声的潜在代码中重构潜在代码。为简单起见,我们仅在图 4 (a) 中展示了去噪阶段。首先,我们将嘈杂的训练片段转发到自动编码器中以提取其潜在代码。然后,我们将其输入到去噪 U-Net 中以学习干净的潜在代码。最后,我们利用解码器使用干净的潜在代码重建原始片段。但是,与现有的视频扩散模型相比,我们新颖的 ShowMaker 包含两种不同的设计,在图 4 (b) 中的模型结构(即时空增强块)和图 4 (c) 中的训练范式(即模式选择)。
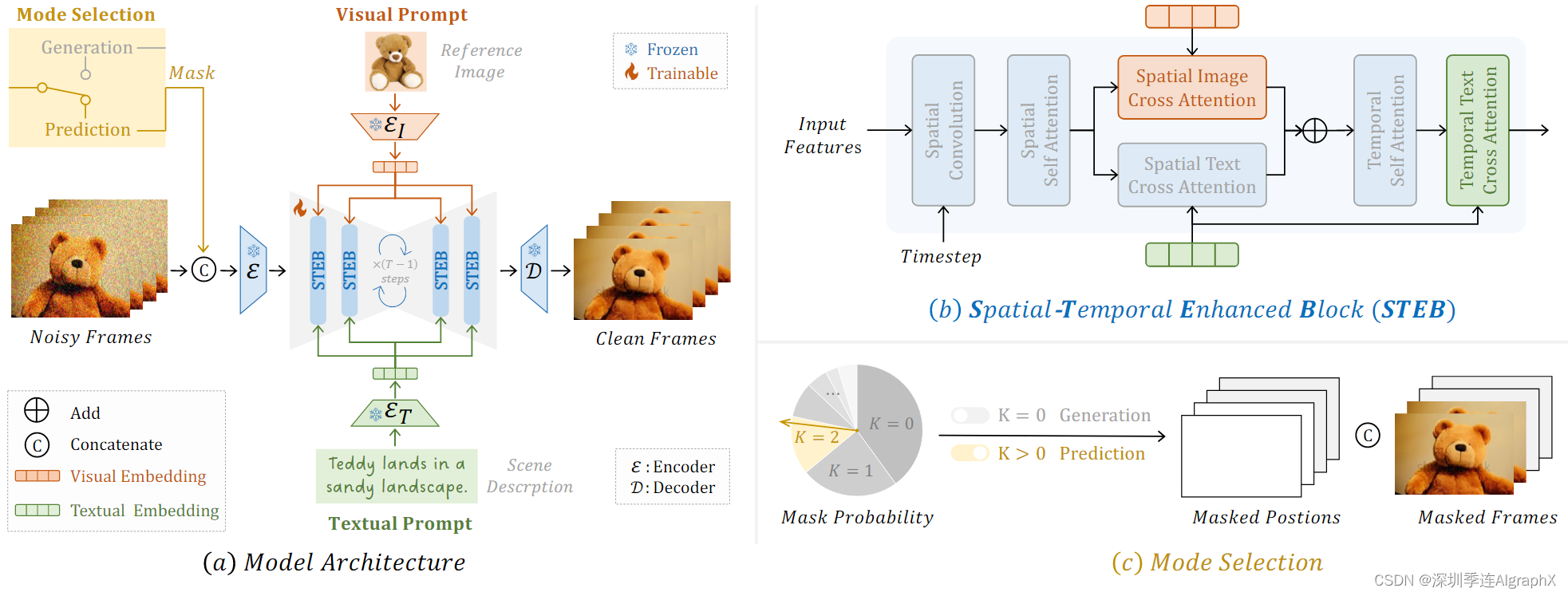
图 4. ShowMaker(a)总体架构。(b)时空增强块(STEB)。通过空间-演员和时间-文本的交叉注意,STEB可以进一步增强片段中演员和脚本的连贯性。(c)模式选择。我们通过掩码帧的概率选择,引入了T2V生成和预测的混合训练范式。
3.2.1 Spatial-Temporal Enhanced Block (STEB)
为了重建训练视频片段的干净潜在代码,去噪 U-Net 中的每个块都包含先前工作中的空间和时间操作。首先,空间操作在片段中分别对每一帧特征进行编码。通常,三个操作继承自文本到图像生成方法,包括空间分辨率(CV)、空间自注意(SA)和空间交叉注意(CA)。

其中 Xin 是训练片段的噪声特征,Ft 是迭代步骤 t 的位置嵌入。为了指导给定文本的去噪,我们使用场景描述Sn作为Eq.(9)中交叉注意的K和V。然而,我们注意到这种空间编码没有考虑演员。因此,在生成片段时,它不可避免地存在演员不连贯的问题。为了解决这个问题,我们引入了一个空间图像交叉注意。
![]()
对于拍摄场景 Sn,我们利用主角(Eq. 4) 在该场景中找到相应的演员。然后,我们利用演员参考图像Rn作为空间交叉注意的视觉上下文。随后,我们通过剧本和演员的互补指导来增强空间嵌入,即权重为 β 的 Zse = Xca + βYca。
在空间编码之后,时间学习片段中跨帧的相关性。因此,典型的操作是沿时间维度执行自注意。
![]()
然而,这种时间操作没有考虑场景文本的约束。在生成视频片段时,它通常会导致文本不连贯。因此,我们引入了一个时间文本交叉注意。
![]()
我们利用场景描述 Sn 作为时间编码的文本上下文。通过空间参与者(等式 10)和时间文本(等式 12)交叉注意,我们的 STEB 可以进一步增强片段中的演员和剧本连贯性。
3.2.2 Mixed Training Paradigm with Mode Selection
如第 3.1.2 节所述,ShowMaker 旨在生成剧本中分配持续时间的视频片段。为此,它利用了推理阶段生成和预测模式的组合。接下来,我们解释了如何训练我们的 ShowMaker 来学习这些模式。如图 4 (c) 所示,我们设计了一种模式选择机制,该机制选择干净片段的 k 帧作为噪声片段的上下文。k=0 设置是指生成模式,因为没有来自干净片段的上下文。或者,k>0 设置是指预测模式,因为干净片段的 k 帧已经可用。目标是从嘈杂的片段中生成其余帧。为了将这两种模式集成到训练中,我们设计了一种概率方式来选择 k。

其中 P(k) 是 k 的选择概率分布。此外,0<m<1 和 0≤m 是手动参数,分别控制 P(k) 的模式选择趋势和保留帧的最大数量。在确定 k 后,我们在干净片段潜在代码上引入了一个帧掩码 Mk
![]()
其中我们只保留 k 帧并屏蔽其余帧。然后,我们将掩码Mk与片段Xnoise和Xk的潜在代码连接起来,
![]()
这产生了输入特征 Xin,用于在 3.2.1 节中训练去噪 U-Net。通过这种简洁的概率方式,我们可以在训练过程中有效地整合生成 (k=0) 和预测 (k>0) 模式。
4. Experiments
Datasets
为了与最先进的模型比较,我们对流行的视频基准(即 UCF-101、Kinetics-400 和 MSR-VTT)进行了零样本评估。
UCF-101 包含 101 个动作类别的视频。我们使用FVD来评估生成的视频与真实视频之间的距离。
Kinetics-400 包含 400 个动作类别视频的数据集。我们使用 FID 来评估视频生成的性能。
MSR-VTT 是一个带有开放词汇字幕的视频数据集,其中 CLIPSIM 和 CLIP-FID 通常用于评估 T2V 生成。
此外,由于这些现有的基准要么只有少量的测试视频,要么只包含没有复杂描述的动作标签,我们建议收集消融研究的评估基准。它被称为 Vimeo11k,我们从 Vimeo 中的 10 个主流类别中收集 11,293 个开放世界视频及其标题。据我们所知,它是零样本视频生成的最大测试基准。
Implementation Details
1)Director & Script & Actor & Voicer
我们选择 GPT-4 作为我们的 LLM 导演来生成剧本。然后我们使用Stable Diffusion XL和Bark作为我们的设计者和语音器来生成参考演员图像,并将剧本转换为语音。
2)ShowMaker
我们选择 SD-1.4 作为我们的基础模型,并遵循 Make-A-Video,添加时间自注意力。然后,我们在每个时序自注意之上添加我们的时间文本交叉注意力。我们将U-Net卷积层的输入通道从4扩展到9,使模型可以将Eq.(15)中的拼接特征作为输入。我们对新添加的通道使用零初始化。我们使用CLIP ViTL/14 作为文本编码器εT。VQ-VAE作为由编码器ε和解码器D组成的自动编码器。此外,我们使用OpenCLIP ViT-H/14 作为图像编码器εI,并在STEB块中添加空间图像交叉注意。扩散步骤 T 设置为 1000。在Eq.(13)中,我们将模式选择的参数设为α = 0.6,m = 6,β = 1。
我们使用公开图像数据集(即Laion400M)和视频数据集(即WebVid10M)进行联合训练。
4.1. Comparison with state-of-the-art
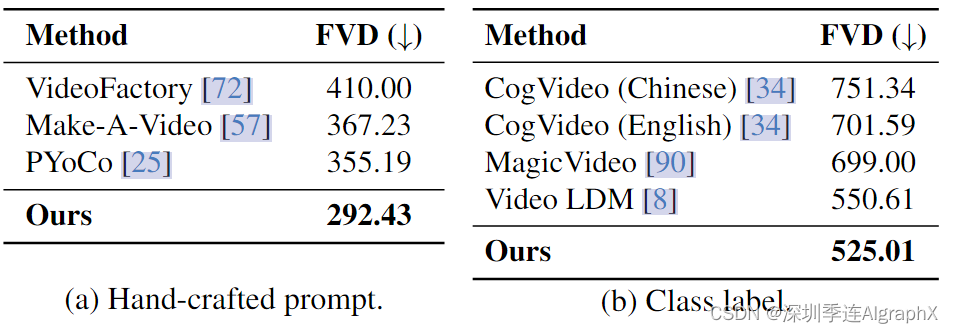
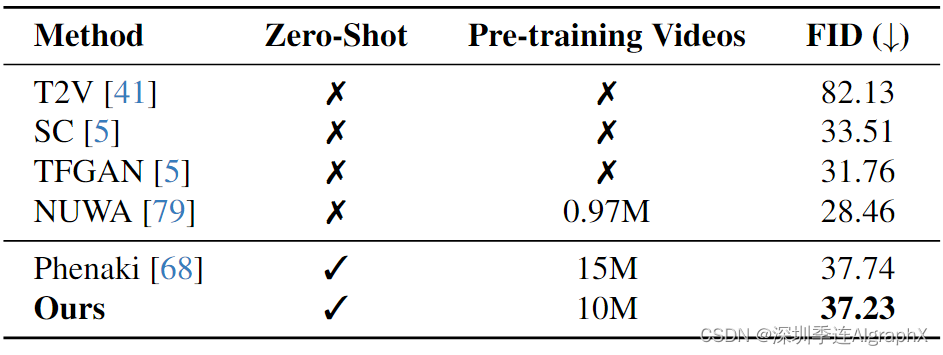
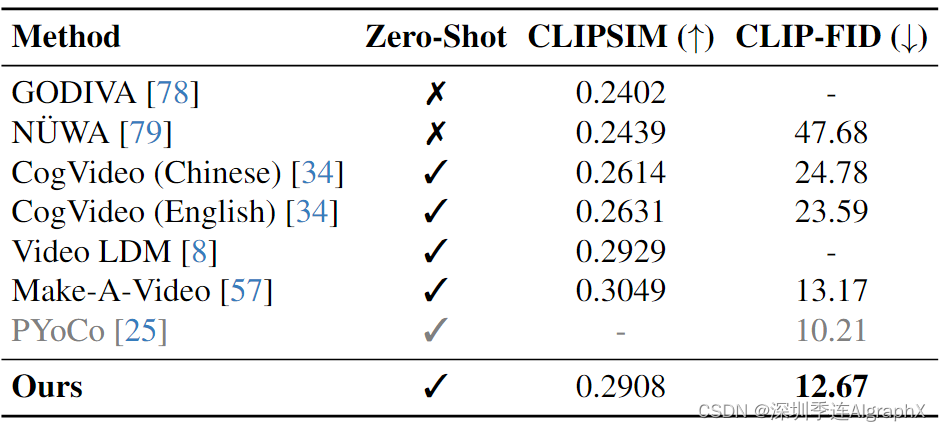

图 5. 长视频生成。UCF-101 (1000帧)的比较。FVD越低,生成性能越好。
4.2. Ablation StudyVlog Generation Process
Vlog Generation Process

表 4,不同生成过程之间的比较。
Spatial-Temporal Enhanced Block
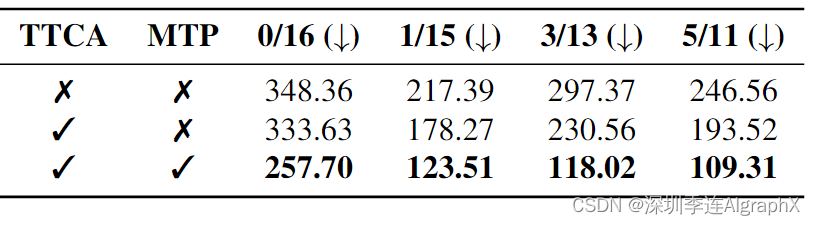
表 5. 时间文本交叉注意和混合训练范式的消融研究。“TTCA”和“MTP”分别表示时间文本交叉注意和混合训练范式。
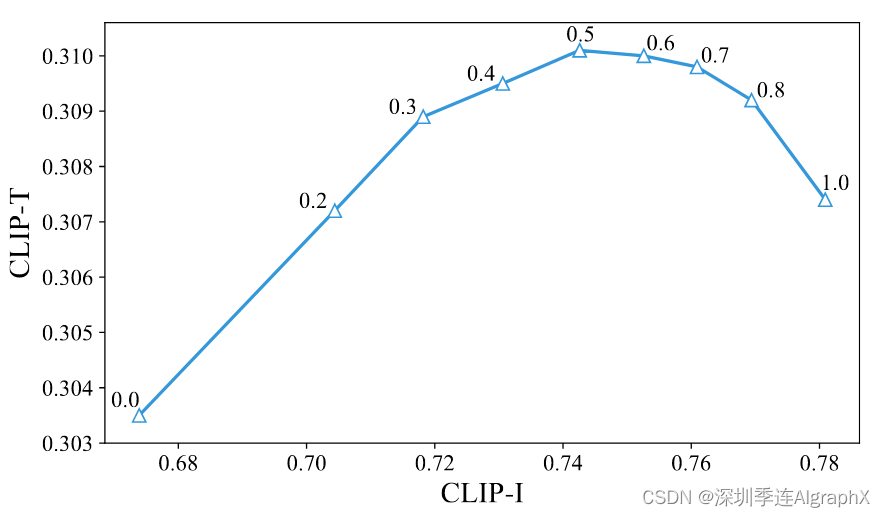
图 6. 空间图像交叉注意消融。曲线上一个点周围的值对应于 β。β=0 表示没有空间图像交叉注意力的原始网络。
4.3. Visualization
首先,通过与著名的 Phenaki 相比,我们可视化了长视频生成。请注意,由于 Phenaki 没有开源代码,我们交替使用官方网站中显示的演示。具体来说,我们将相同的故事描述输入到我们的 Vlogger 中。如图 7 所示,我们的Vlogger显示出更好、更多样化的视频内容。此外,根据我们的 LLM 创建的脚本,我们的 Vlogger 充分展示了持续时间更长的故事(即 7min59s)。

我们进一步可视化了 ShowMaker 的 T2V 视频生成和预测消融。如图 8 所示,ShowMaker通过设计,在生成和预测性能方面有了显著的改进。此外,它可以利用空间演员交叉注意中的视觉提示来区分文本提示中的“Teddy”概念。

5. Conclusion
在本文中,我们介绍了一种AI通用系统 Vlogger,用于从开放世界描述中生成超过 5 分钟的视频博客 vlog,而不会丢失剧本和演员上的视频时空连贯性。此外,我们提出了一种新颖的视频扩散模型 ShowMaker,用于提升最先进的 T2V 生成和预测。最后,我们发布了所有模型、数据和代码,允许为开放世界中的长视频生成开发进一步的设计。
本专题由深圳季连科技有限公司AIgraphX自动驾驶大模型团队编辑,旨在学习互助。内容来自网络,侵权即删。文中如有错误的地方,也请在留言区告知。
Vlogger-https://arxiv.org/abs/2401.09414
https://github.com/zhuangshaobin/Vlogger



![[JUCE]从一个有关右值引用的bug,探幽移动语义](https://img-blog.csdnimg.cn/direct/14da8e12c1ae42dabb5e31cae1f35c45.png)